How to Upload Source Code to Digital Ocean
Lessons Learned: Digital Ocean for Python 3
This entry is part of an ongoing serial. I spend a lot of time trying out new technologies. More often than not, because of a recommendation similar: "Y'all should try [insert technology hither], information technology's super like shooting fish in a barrel!".
This turns out to rarely exist the instance, so every time I invest hours into trying to go something to work, I'll publish my solution, and any tips and tricks I learned along the way.
Digital Ocean is a deject based server provider, with very reasonable plans that allow yous to shift computation off your computer and into the cloud, saving you time and keeping your calculator fresh!
I initially followed Tomi Mester'due south tutorial to get DO set up, but quickly realised I wanted to do more (although I highly recommend the rest of the series, Data Scientific discipline from the Control Line). This turned out to be a petty tricky, then here'southward my walkthrough.
1. The Signup
Head over to Digital Bounding main and create an business relationship, using either Paypal or a Credit Card (if you employ the link above you'll go some free credit and and then will I. If you don't desire to do that, just click here).
If yous're a student, y'all can also get $l in credit from the Github Student Pack (which I also highly recommend). Digital Bounding main initially wouldn't accept my lawmaking when I signed upwardly, just I submitted a support ticket and they credited it inside a few hours.
2. Your First Droplet
Aerosol are server infinite which is specifically reserved for you lot. You're merely ever charged when you have a droplet (regardless of whether it'south on or off), but creating and destroying them is easy, then don't worry virtually existence charged when y'all're not actively using it.

In the top correct-hand corner of your DO dashboard (or in the centre if you don't already have any aerosol), await for the Create Droplet button.
Clicking information technology takes you to the setup page. The showtime option is epitome:
You won't have a Snapshots choice (more on this later), just the default choice (Ubuntu) is what we desire, so you don't have to do anything hither.
The second option is pricing plans:

Hither you lot can see what y'all're getting, and how much it costs. You're charged per hour that the droplet exists, and so unless you're not deleting it when you're washed, your cost will be a lot lower than the per-month costs quoted.
Which one you selection depends on a few things:
- How big are the files you'll be loading into memory? (pandas dataframes for example). The kickoff line nether the price is how much memory / how many CPUs the droplet has.
- Tin your process be distributed? (recall
sklearn njobs= -1). If it tin, multiple CPUs will speed up processing. Likewise, if yous have a lot of information, splitting in half and running the jobs at the same fourth dimension will save fourth dimension, just is only possible on droplets with more than i CPU. - How large are the information files you'll be uploading? This is the 2d line, the corporeality of storage bachelor.
- The concluding line represents the amount of information transfer (upload + download) that is allowed. Unless you're doing something really crazy, 1TB is more than than enough.
I recommend the $5/month option to start. Information technology's pretty easy to upgrade if you're hitting a wall.
The 3rd step is Add Cake Storage. Yous don't need this initially.
The forth is choosing a data center:
I'g in Ireland, so I chose London. Choose whichever is closest to you.
The final footstep is to enable monitoring (more on this later) and requite your droplet a really useful name!
Then hit create droplet, and after a infinitesimal or then, y'all'll be all set up!
3. Initial Setup and Snapshots
When you're done, you'll become an email from Digital Sea with an IP accost, username and password. Copy the IP address, fire up your command line and enter:
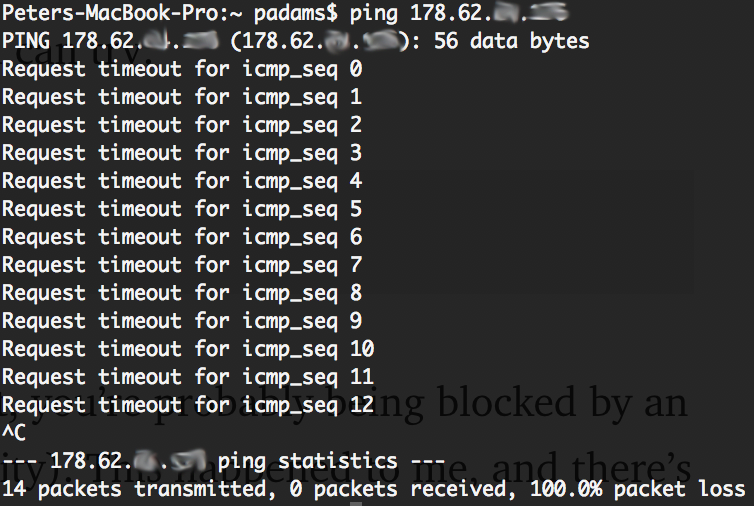
ssh root@[IP Address] If this hangs and zippo happens, yous can try:
ping [IP Accost] and see if y'all accept a connection. If non, yous're probably being blocked past an external firewall (your work or university). This happened to me, and there's not a lot you can practise:
If you practise go a response from ssh root@[IP Address] , at that place will exist a agglomeration of text asking you if y'all want to proceed. Write yes and press enter.
Yous'll and then be asked to enter the password. Re-create and paste that in from the email and hit enter. You'll and so need to alter the root password. Make this pretty secure equally y'all won't be logging into root that often, only if someone else does they can totally wreck your droplet.
Next, you want to create a user:
adduser [username] where [username] is anything yous desire.
You'll accept to create a countersign for this user, and it'll ask for a bunch of personal information. Enter this if you similar, or skip it (press enter), it doesn't matter.
Side by side, give your new business relationship permissions to do stuff on the server
usermod -aG sudo [username]
gpasswd -a [username] sudo This gives yourself the power to make changes without having to be logged into root.
Finally, change the fourth dimension zone:
sudo dpkg-reconfigure tzdata and select your current city.
Squeamish! We're all fix on root. Now we can go out and check out your user business relationship.
exit ssh [username]@[IP Address]
In one case yous've logged in, the kickoff step is to configure your bash contour to make your life easier.
nano .profile If you haven't used Nano earlier, it's a elementary text editor. Apply arrow keys to movement, Ctrl+k to cut a line, Ctrl+u to paste a line, Ctrl+o to save, Ctrl-x to exit.
Y'all tin can add together aliases hither (shortcuts) to make life easier. I use Python iii and Pip 3, and then I generally avoid defoliation by setting:
alias python="python3"
alias pip="pip3" I likewise hate typing nano ~/.profile when I want to change or cheque my bash profile, then I alias that too:
allonym obp="nano ~/.profile"
allonym sbp="source ~/.contour" You lot tin also add any other aliases here. Save information technology with Ctrl+o and exit with Ctrl-x .
To implement these changes, you demand to source the profile:
source .profile (As a side note, you can't use new alias shortcuts before you've sourced them, so only inbound sbp won't work nonetheless, merely will after you've sourced it the long manner once).
apt-get is a bit similar Pip for the command line, and should be updated before we go any further.
sudo apt-get update Python 3 is already installed, just Pip isn't, and so allow'southward go ahead and get and update that:
sudo apt-get install python3-pip
pip install -upgrade pip Now you can pip install all your regular Python packages! Well, you can in a 2nd. For some reason, Matplotlib and a few other packages have problems with Ubuntu, but you tin can solve these past running:
sudo apt-get install libfreetype6-dev libxft-dev
sudo apt-go install python-setuptools Sweet, now y'all can go nuts with pip3 install . If you have a requirements.txt file which you lot employ for all your installations, you lot can run that now.
Finally, AG is a great search tool for the command line which doesn't come as standard, so you lot can install that too if y'all'd similar:
sudo apt install silversearcher-ag Perfect, you're all prepare up! At present, this was quite a lot of work, and it would suck to have to exercise this each fourth dimension. That'south where Digital Ocean snapshots come up in!
This is a way to 'save-every bit' your current droplet, so that when y'all create a new droplet next fourth dimension, you can only load that epitome and you'll starting time exactly where y'all left off! Perfect.
Powerdown your droplet using sudo poweroff and caput over to the Snapshots carte du jour-particular on your Digital Ocean droplet page:
Snapshots aren't free, they cost $0.05/Gb/month. My snapshot taken with Pandas, Numpy, Matplotlib and a few other packages install was 1.85Gb, so that's about $1.xi per twelvemonth. Not bad considering it'll salvage you lot 10 minutes each time you lot fix a droplet!
Every bit your droplet is already powered down, hitting the 'Have Live Snapshot' button and Digital Bounding main will exercise the remainder.
A side notation hither, it doesn't appear you can read a snapshot into a cheaper droplet pricing scheme. Just something to proceed in mind.
If you lot ever desire to upgrade your pricing scheme, caput to the Resize carte item. Again, y'all tin can't downgrade here and if you want to, you lot'll need to create a droplet from scratch and echo the higher up steps.

To plow your droplet dorsum on, head to Digital Body of water and in the superlative-right paw corner of the droplet page there'south an on/off toggle. Turn it back on and you lot're ready to upload data.
4. Uploading Data via SFTP
Now, if you accept the information on your personal computer and want to transport it up to the deject, y'all'll need to do so via SFTP (Secure File Transfer Protocol). This is fairly easy, albeit information technology non lightening fast.
To showtime, brand an SFTP connection:
sftp [username]@[IP Address] At present, you can apply the normal command line functions like cd ,ls and pwd to move effectually the file system on the server. All the same, for some reason, autocomplete (tab) doesn't piece of work on SFTP. For that reason, I suggest uploading all your files and code into the abode directory, and the logging back in with ssh and moving stuff effectually using mv and autocomplete. Trust me, it's much easier.
That'southward on the server side, merely how about moving effectually on your personal computer? The same commands piece of work, just you demand to prefix them with an additional l , that is lcd , lls and lpwd . Manoeuvre your style to the directory where the files are held on your local, and then upload them to the server using:
put [localFile] or for a whole directory:
put -r [localDirectory] This isn't fast, for my ane.5Gb data files it took virtually twenty minutes each. Annoying, but in that location'southward non much you can do. You can upload in parallel, merely this means opening up a new command line tab and logging in with SFTP again, plus both connections ho-hum downwardly by half, so the total time is the same :(
You can see how much of you storage you've used by running:
df -h For future reference, downloading files from the server is as simple as:
get [remoteFile] or
go -r [remoteDirectory] At present, in one case your information files are upwardly on the server, you tin can upload your python scripts besides. Make certain that if your local directory configuration is different to the remote, to change any file locations in the lawmaking.
Deleting files from the server is as well slightly different to locally, as rm -rf directory doesn't work. You need to rm filename to delete a file, or empty a directory then rmdir directory to delete a folder.
This is enough to get you lot started, merely if you're interested in more advanced options, in that location's a good tutorial hither.
I thoroughly recommend testing all your lawmaking locally (I use PyCharm, which is bully and has a free student license besides) on pocket-size subsets of the data, and so when it's working, SFTP'ing the code to the server and running it once. Troubleshooting over remote connectedness can exist annoying.
5. Running Computations
Now, y'all're all set up up to run some computations. Log back in with ssh , organise all your files, and run whatsoever code with python filename.py as you would on your local reckoner.
If you become a Killed response when you attempt and run some code, information technology means you don't accept enough memory to complete the chore. Y'all take two options. Either powerdown and upgrade your pricing plan, or create a Swapfile (more below).
Printing error logs volition give you some more data on what has gone wrong:
sudo cat /var/log/kern.log You can monitor task progress on the Digital Bounding main dashboard that shows you some squeamish graphs of usage:
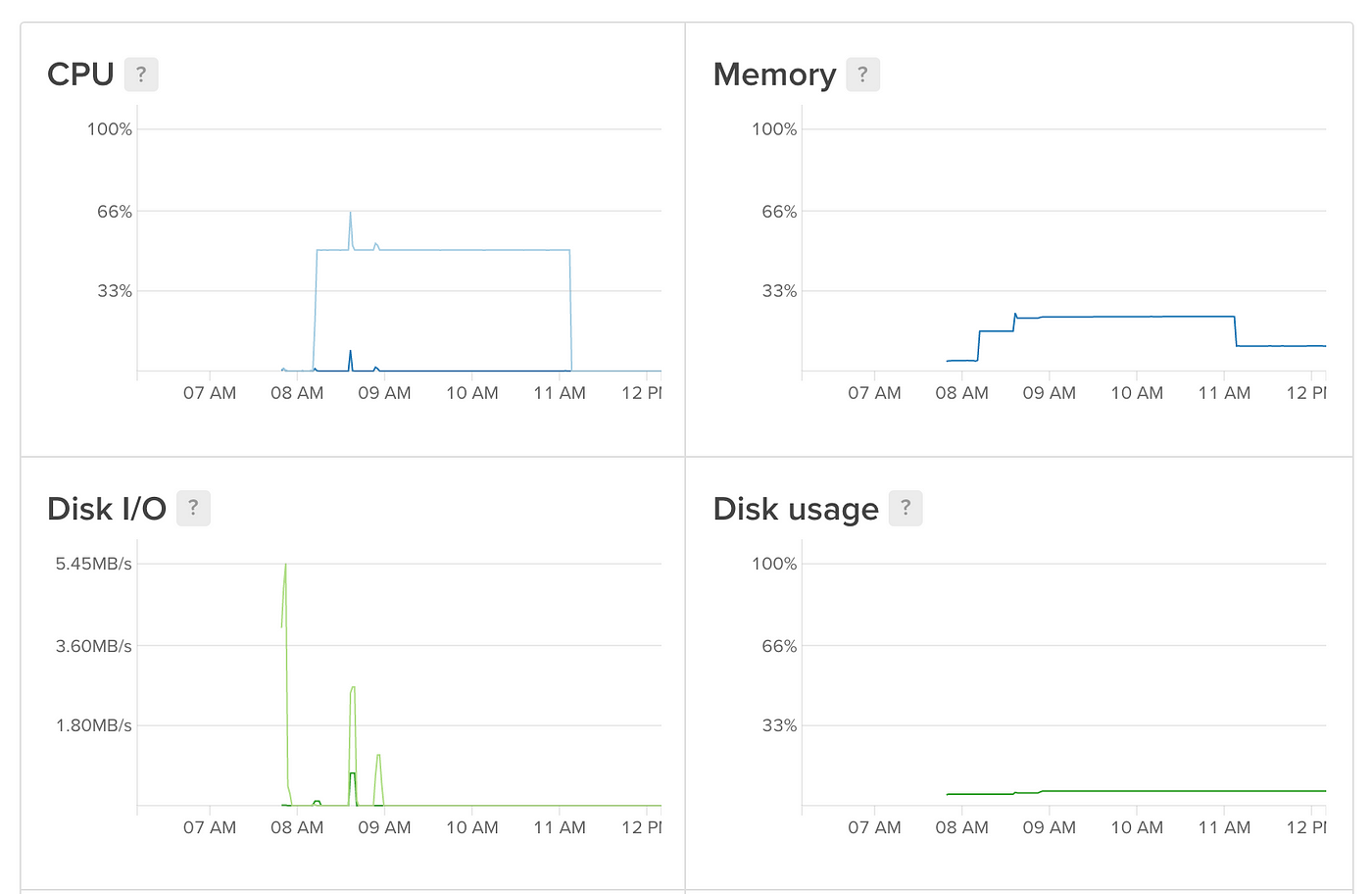
You lot tin can fifty-fifty set alerts to become an email when a metric drops below a certain level, like CPU, which can be used to let yous know when a job is washed! Click on 'Create Alert Policy' at the summit of the Graphs page to set something similar this up.

One time you lot're done with your processing, you can use SFTP to get your files from the cloud, and and then destroy the droplet so y'all don't continue to be charged for information technology!
Now for a discussion of alarm; exist careful when writing to file.
I wasted a lot of time running a pandas apply function, then using df.to_csv('filename') to save the results. If there are any bug with the server (which there may well be, more than below), you'll lose everything before it's written to file.
My workaround was to loop over the entire data frame and print the result line by line:
for row in range(len(df.alphabetize)):
col_value = df.ix[row,:].values[2]
ind = df.index[row]
with open up("./data_file.csv", "a") as file:
file.write(ind + ',' + function(col_value) + '\n') This really wrote my data to csv , then I could but merge the data frames on their alphabetize values to line things upwards.
consequence = pd.concat([df, new_data], centrality=1, join_axes=[df.alphabetize]) Not as pretty equally utilise , but sometimes when dealing with data of this size, it's better to trade-off some performance to ensure you're actually getting the data you want!
6. Improving Functioning
I of the best things well-nigh DO is that you can have upwards to 20 CPUs in your droplet, which can all run processing in parallel. This is much faster than just processing all your data on one CPU.
Yous should know how many CPUs your program has, but if non, y'all can use the following code to bank check:
cat /proc/cpuinfo | grep processor | wc -l I take 2, so this means I tin run two processes simultaneously. From what I tin can see, this doesn't dull either process, so y'all can finer work twice as fast if y'all split your task in half. The best way to do this is to split whatever data you have in half, then run the same script on each. In Python, I'd add the following code later importing your information with pandas.
import sys number_of_cores = 2
length_of_df = len(df.index)
stream = sys.argv[i] if stream == 1:
start = 0
terminate = length_of_df // number_of_cores
else:
start = length_of_df // number_of_cores
end = -i data_to_process = df.iloc[first:end,:] output_filename = "output_data_" + str(sys.argv[one]) + ".csv
Then from the command line you lot tin can run
python script.py 1 which will procedure the showtime half of the data, and
python script.py 2 which will process the second. Combine the two data files at the end using
true cat output_data_2.csv >> output_data_1.csv 7. Troubleshooting
My biggest headache was getting my scripts to run to completion. For some reason (that I never figured out), the server would only cease running my processing, and then I'd have to restart it manually. My usage graph looked like this:
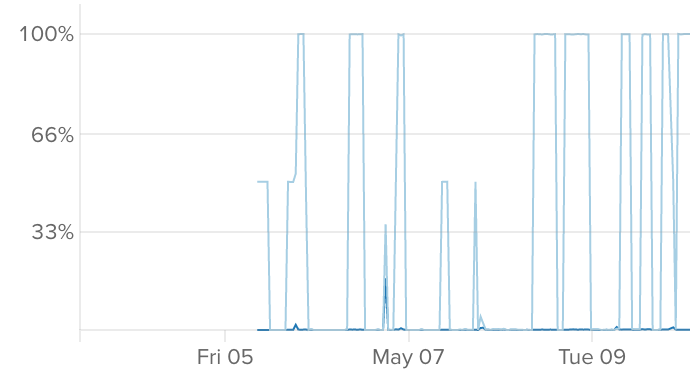
Really non ideal, especially as my college firewall blocked my connexion, and so I had to wait until I got home to restart things.
The first part of my solution was to figure out the re-get-go point in the for loop, so I wouldn't be re-doing ciphering. I used the subprocess module and so I could run control line functions from within a python script:
import subprocess stream = int(sys.argv[1]) if stream == 1:
end = 3387532
information = "./data.csv" a = subprocess.Popen(['wc', '-50', data], stdout=subprocess.Piping)
wc = int(a.communicate()[0].rstrip().decode().separate(' ')[0]) start = 0 + wc
My full number of rows in my file was six,775,065, and I had 2 CPUs, so like to a higher place, I gear up my stop index to half of the file size. The subprocess.Popen returns the results of a command line office, in this case, wc -fifty ./data.csv , or checking the number of rows in the output data. stout=subprocess.PIPE makes the output easier to work with. The next line retrieves the actual line count of the output data, so first is set to appropriately.
This meant whenever things crashed I could simply run:
python script.py 1;
python script.py ii; on different terminal screens and both halves of my data would restart when the advisable place. A skillful event!
However, this didn't practise anything to cease my server crashing, nor restart processing automatically afterwards it did. Some inquiry led me to crontabs, which allow functions to be evaluated at specific time periods. You tin can see electric current crontabs with:
crontab -50 At that place shouldn't exist anything there, and so you tin can go alee and create one using:
crontab -e The beginning time, y'all'll be asked to select a text editor, Nano is the easiest, merely this can exist changed later by running'select-editor'
I won't get into too much detail, but the concluding line of the file looks like this:
# chiliad h dom mon dow command This stands for minute, hr, day-of-month, month, day-of-calendar week and command. This allows you to set a command to exist run at a specific interval. A few examples:
*/x * * * * eval "python3 script.py" Runs a script every 10 minutes.
10 * * * * eval "python3 script.py" Runs a script at x minutes past the 60 minutes every hr.
10 5 * * 3 eval "python3 script.py" Runs a script at 10 by five every Wednesday.
You become the idea. For me, I wanted to bank check every ten minutes if my server had crashed, and if so, restart it. So my crontabs were:
*/ten * * * * eval "python3 sys_test_1.py"
*/10 * * * * eval "python3 sys_test_2.py" (I had to accept two considering of the difficulties of running python scripts on separate CPUs from the same file, this was just easier). There's more than of a detailed caption of crontabs here if yous're interested.
Then my file sys_test_1.py looked something similar this:
data = "./data.csv" a = subprocess.Popen(['wc', '-l', data], stdout=subprocess.PIPE)
wc_1 = int(a.communicate()[0].rstrip().decode().split(' ')[0]) if wc_1 > 3387530:
exit()
else:
fourth dimension.slumber(xv) b = subprocess.Popen(['wc', '-50', data], stdout=subprocess.PIPE)
wc_2 = int(b.communicate()[0].rstrip().decode().carve up(' ')[0]) if wc_1 == wc_2:
subprocess.call(["python3", "run_comp.py", "i"])
So I check the number of lines in my file, and if it's over some threshold (ie close to the end of the required computation), exit. Otherwise, await 15 seconds and check the file length once again. If they're the same, it implies no computation is ongoing, so it calls the ciphering script from the command line.
Notice I've specifically called 'python3' , fifty-fifty though I have an alias prepare so allonym python="python3" in my bash contour. Calling python scripts with subprocess appears to ignore aliases, and so keep that in listen.
So with this running every 10 minutes, I had a way to bank check if anything was wrong, and if information technology was, restart processing automatically. Since I fixed this, my server has run not-end, with any crashes defenseless apace and processing restarted.
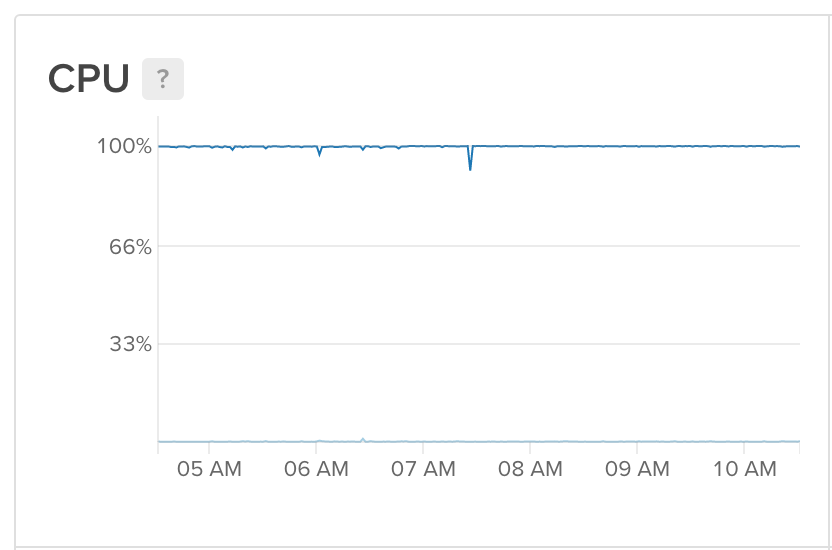
Perfect!
And in that location you accept it! You now know how to create, setup, upload data, and run scripts on a cloud server! Big Data, here you come!
There's more than of an explanation on swapfiles below, but that'south optional reading…
If y'all liked this post, delight click the ❤ button to let your followers know, or allow me know your thoughts below or on Twitter @padams02.
Swapfiles
Swapfiles are a way to give your droplet extra memory by partitioning office of the difficult drive. That fashion, when the system runs out of memory, it tin save some data to disc and retrieve information technology later. This will let you practise more with cheaper plans, but is considerably slower. Continue in mind that information technology's probably better just to upgrade your plan.
To create a swapfile, run
sudo fallocate -fifty 4G /swapfile where 4G represents the size of the file, ie four gb. This is the size that y'all want the retentivity to accept. Too large and you won't have room for your other files, besides pocket-size and you'll all the same run out of retention. 4 gb should be fine.
You demand to then give write permissions to that directory, create the swapfile, and actuate it:
sudo chmod 600 /swapfile
sudo mkswap /swapfile
sudo swapon /swapfile Open upwardly the fstab file:
sudo nano /etc/fstab and add to bottom of the file:
/swapfile none bandy sw 0 0 There's a parameter called swappiness (crawly name) that sets how much and how often memory is swapped to disc. The higher the value, the more frequently information technology swaps. We don't want information technology to swap that much, so we want to change the default value (60%) to 10%.
sudo sysctl vm.swappiness=10 To set this as default, open:
sudo nano /etc/sysctl.conf and add together to bottom of the file:
vm.swappiness=10 augustinedrablent.blogspot.com
Source: https://towardsdatascience.com/lessons-learned-digital-ocean-for-python-3-e2442db4246f
{kind=link}
Post a Comment for "How to Upload Source Code to Digital Ocean"